Persisted Queries
Use GraphQL queries to create pre-defined endpoints as in REST, obtaining the benefits from both APIs.
Description
With REST, you create multiple endpoints, each returning a pre-defined set of data.
| Advantages | Disadvantages |
|---|---|
| ✅ It's simple | ❌ It's tedious to create all the endpoints |
✅ Accessed via GET or POST | ❌ A project may face bottlenecks waiting for endpoints to be ready |
| ✅ Can be cached on the server or CDN | ❌ Producing documentation is mandatory |
| ✅ It's secure: only intended data is exposed | ❌ It can be slow (mainly for mobile apps), since the application may need several requests to retrieve all the data |
With GraphQL, you provide any query to a single endpoint, which returns exactly the requested data.
| Advantages | Disadvantages |
|---|---|
| ✅ No under/over fetching of data | ❌ Accessed only via POST |
| ✅ It can be fast, since all data is retrieved in a single request | ❌ It can't be cached on the server or CDN, making it slower and more expensive than it could be |
| ✅ It enables rapid iteration of the project | ❌ It may require to reinvent the wheel, such as uploading files or caching |
| ✅ It can be self-documented | ❌ Must deal with additional complexities, such as the N+1 problem |
| ✅ It provides an editor for the query (GraphiQL) that simplifies the task |
Persisted queries combine these 2 approaches together:
- It uses GraphQL to create and resolve queries
- But instead of exposing a single endpoint, it exposes every pre-defined query under its own endpoint
Hence, we obtain multiple endpoints with predefined data, as in REST, but these are created using GraphQL, obtaining the advantages from each and avoiding their disadvantages:
| Advantages | Disadvantages |
|---|---|
✅ Accessed via GET or POST | |
| ✅ Can be cached on the server or CDN | |
| ✅ It's secure: only intended data is exposed | |
| ✅ No under/over fetching of data | |
| ✅ It can be fast, since all data is retrieved in a single request | POST |
| ✅ It enables rapid iteration of the project | |
| ✅ It can be self-documented | |
| ✅ It provides an editor for the query (GraphiQL) that simplifies the task |

Executing the Persisted Query
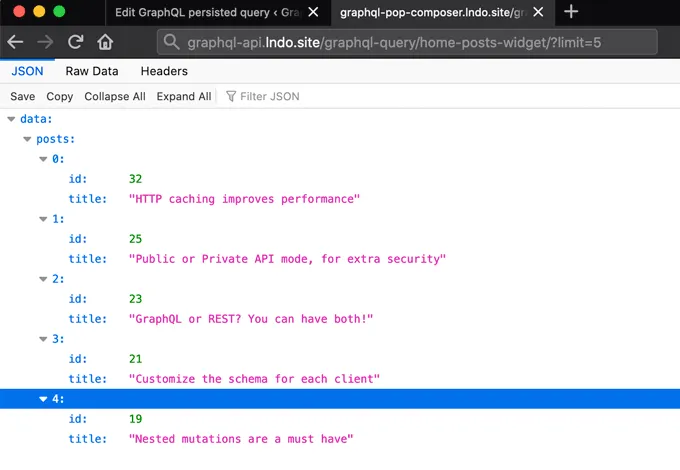
Once the persisted query is published, we can execute it via its permalink.
The persisted query can be executed directly in the browser, since it is accessed via GET, and we will obtain the requested data, in JSON format:
Creating a Persisted Query
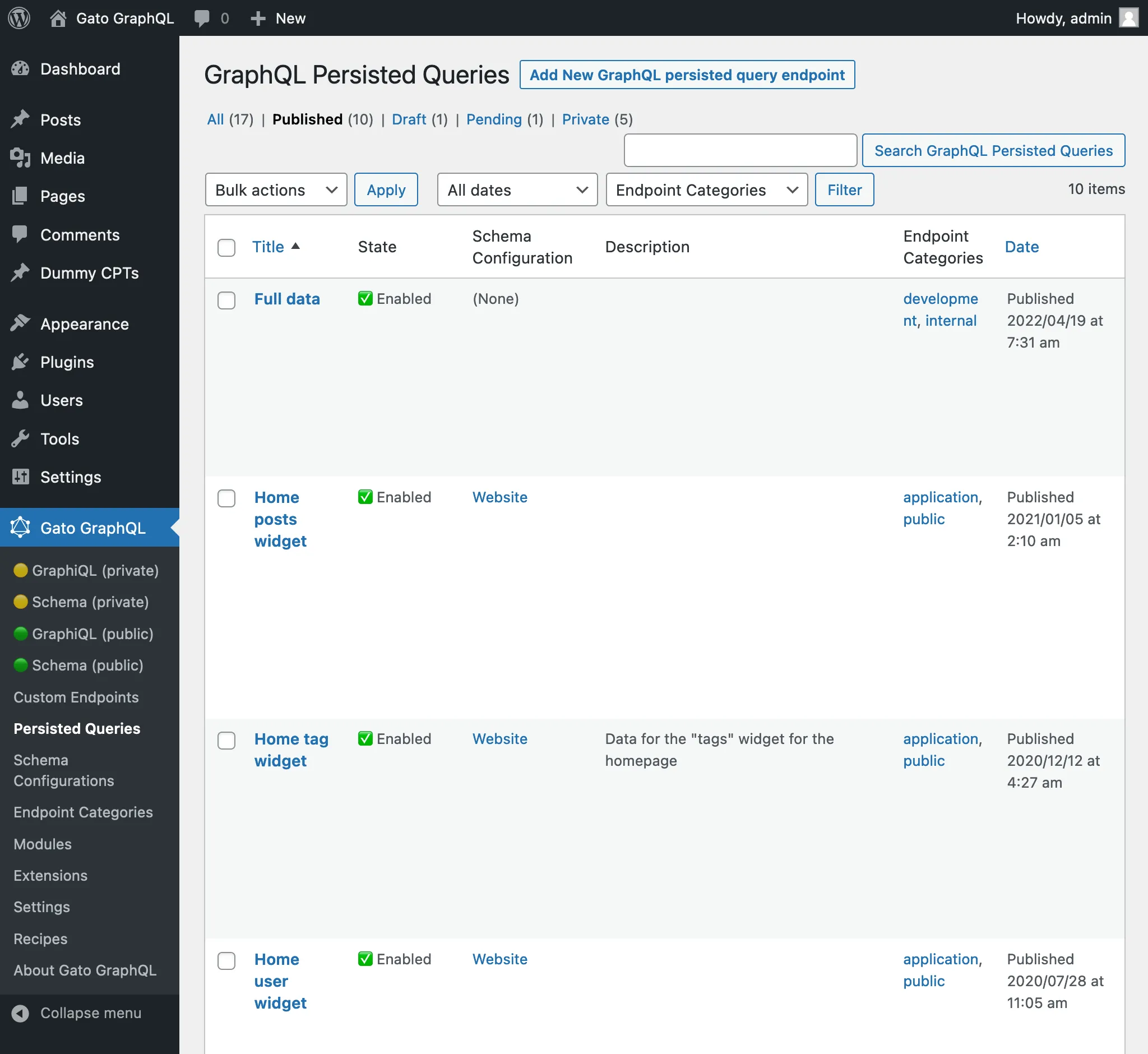
Clicking on the Persisted Queries link in the menu, it displays the list of all the created persisted queries:
A persisted query is a custom post type (CPT). To create a new persisted query, click on button "Add New GraphQL persisted query", which will open the WordPress editor:
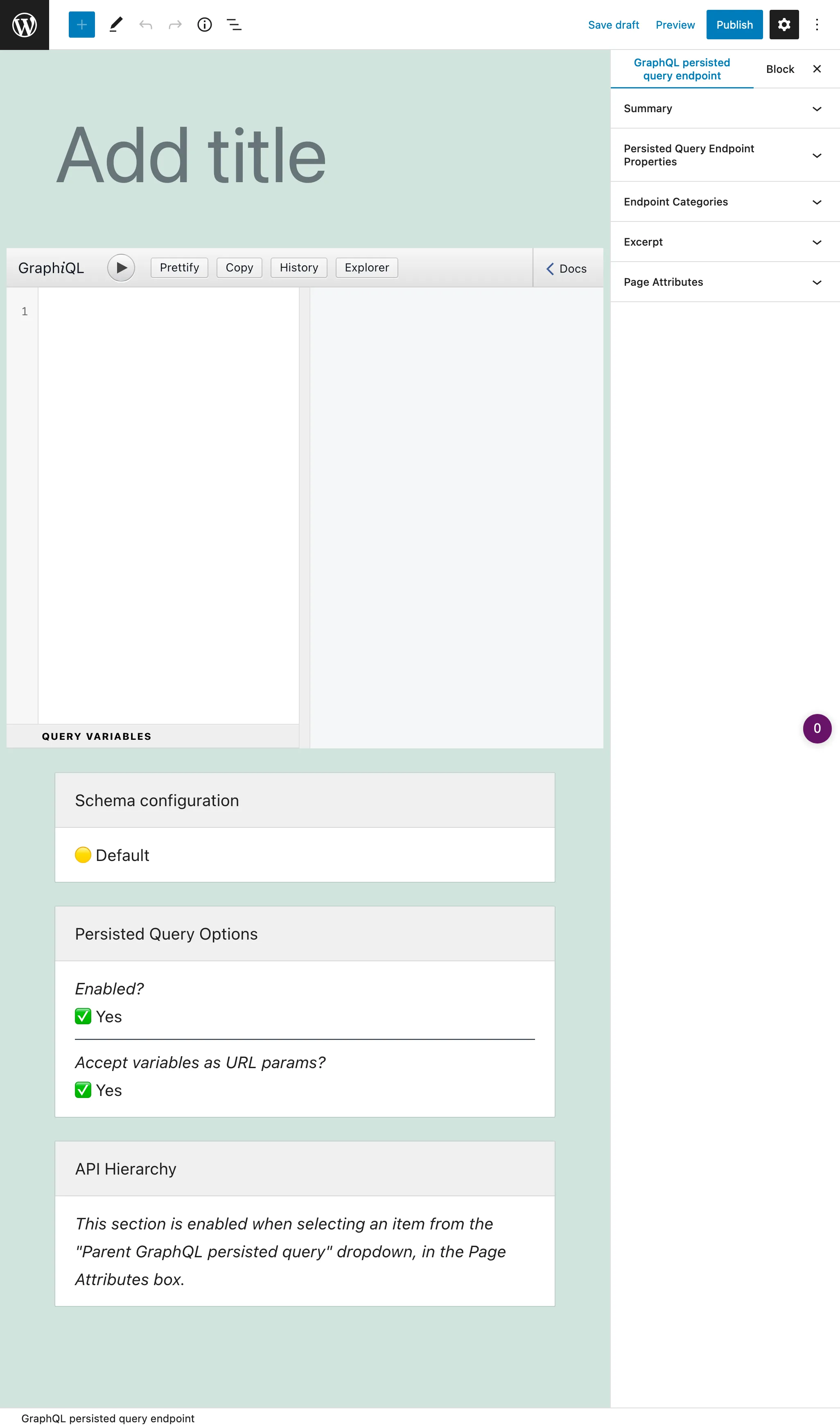
The main input is the GraphiQL client, which comes with the Explorer by default. Clicking on the fields on the left side panel adds them to the query, and clicking on the "Run" button executes the query:

When the query is ready, publish it, and its permalink becomes its endpoint. The link to the endpoint (and to the source) is shown on the "Persisted Query Endpoint Overview" sidebar panel:
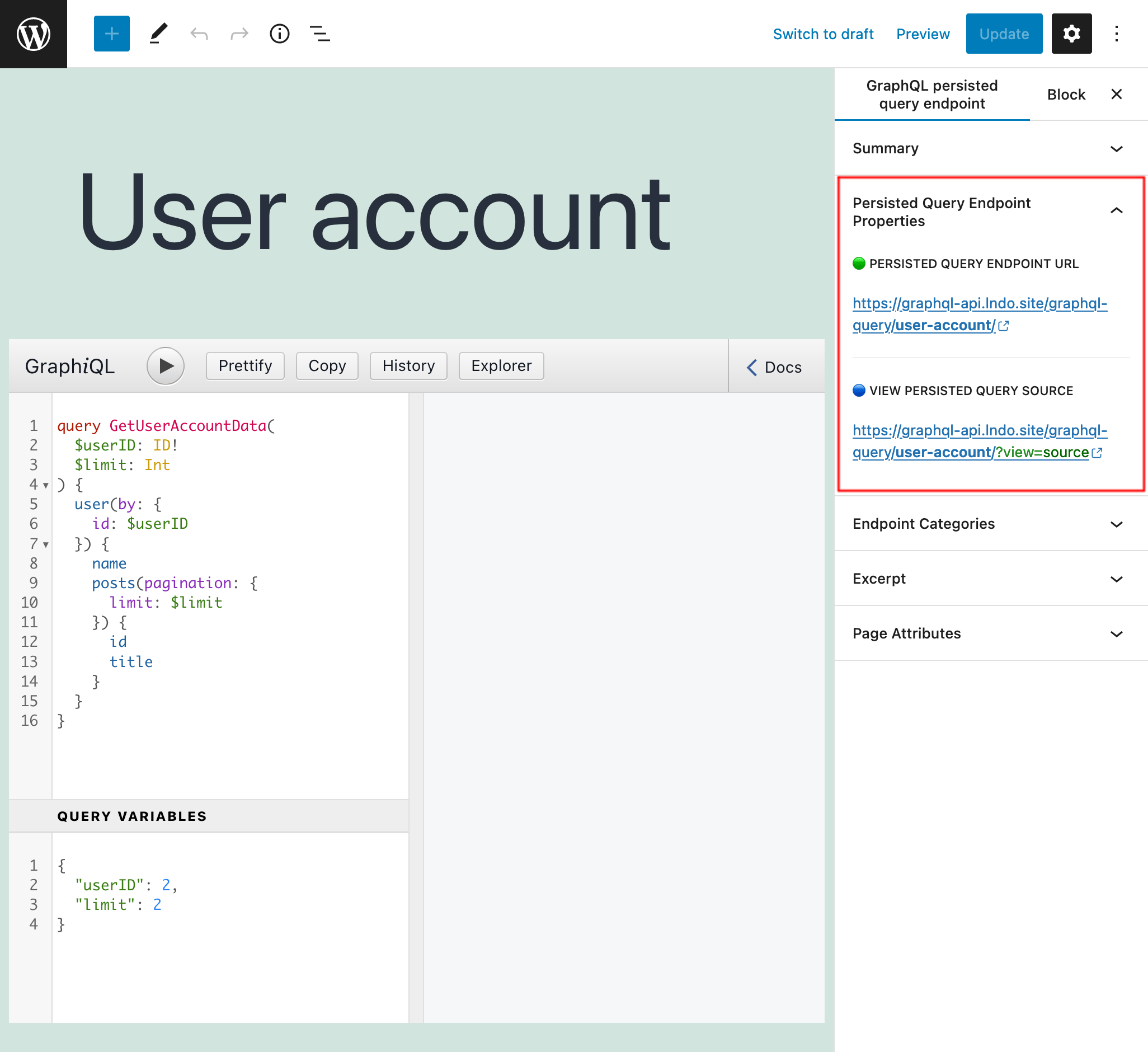
Appending ?view=source to the permalink, it will show the persisted query and its configuration (as long as the user is logged-in and the user role has access to it):

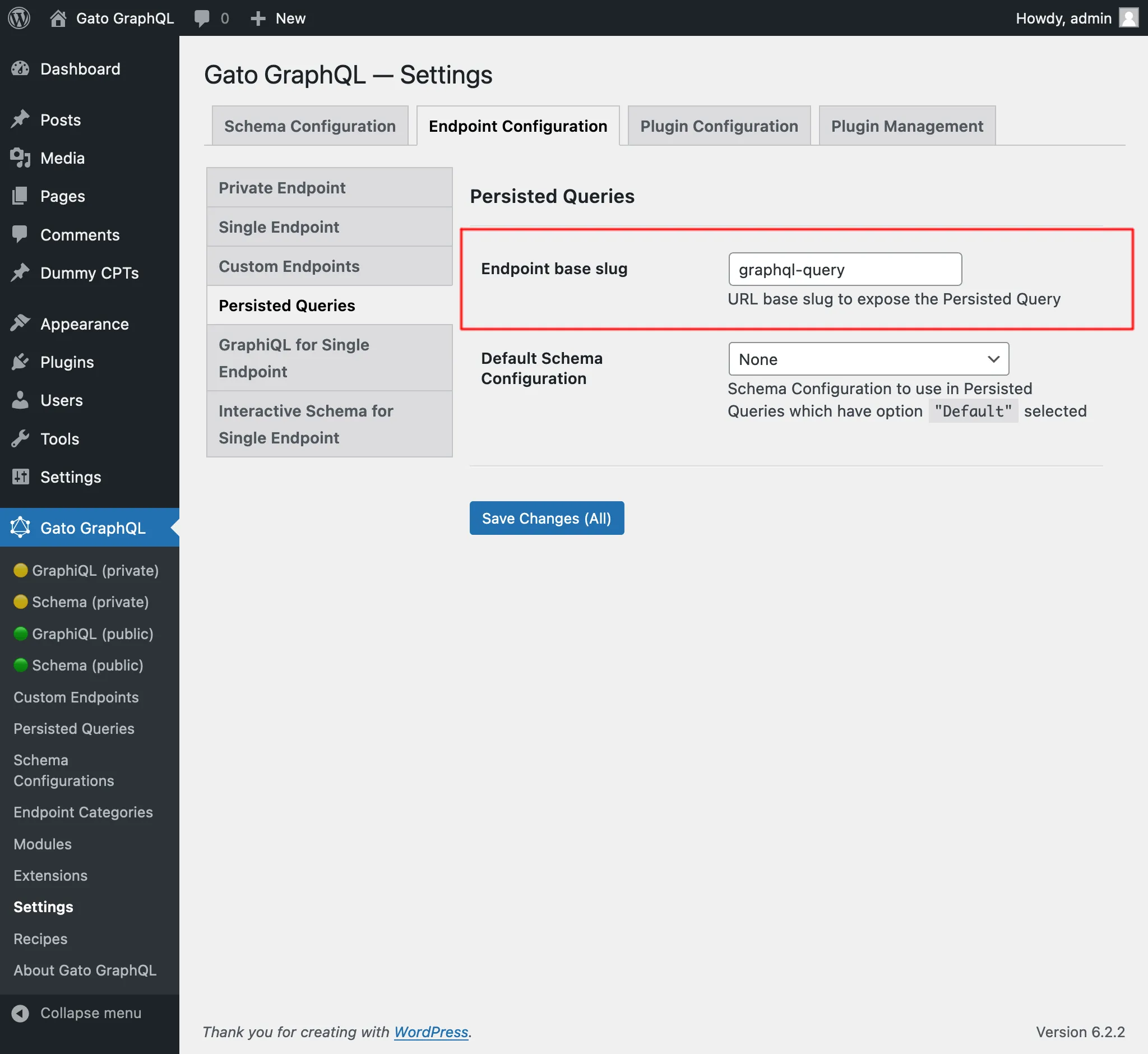
By default, the persisted query's endpoint has path /graphql-query/, and this value is configurable through the Settings:
Schema configuration
Defining what elements the schema contains, and what access will users have to it, is defined in the schema configuration.
So we must create a create a schema configuration, and then select it from the dropdown:

Organizing Persisted Queries by Category
On the sidebar panel "Endpoint categories" we can add categories to help manage the Persisted Query:
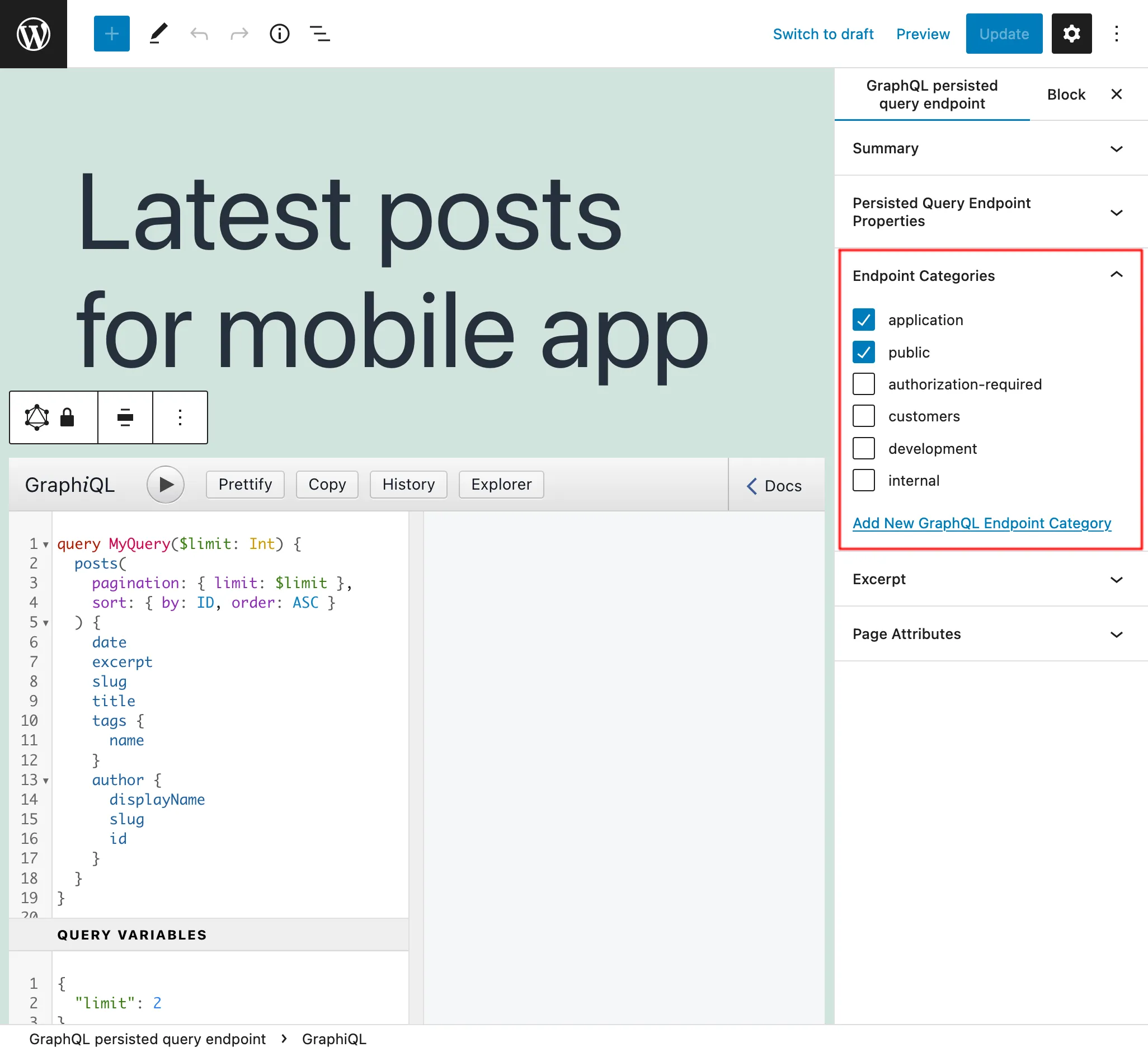
For instance, we can create categories to manage endpoints by client, application, or any other required piece of information:

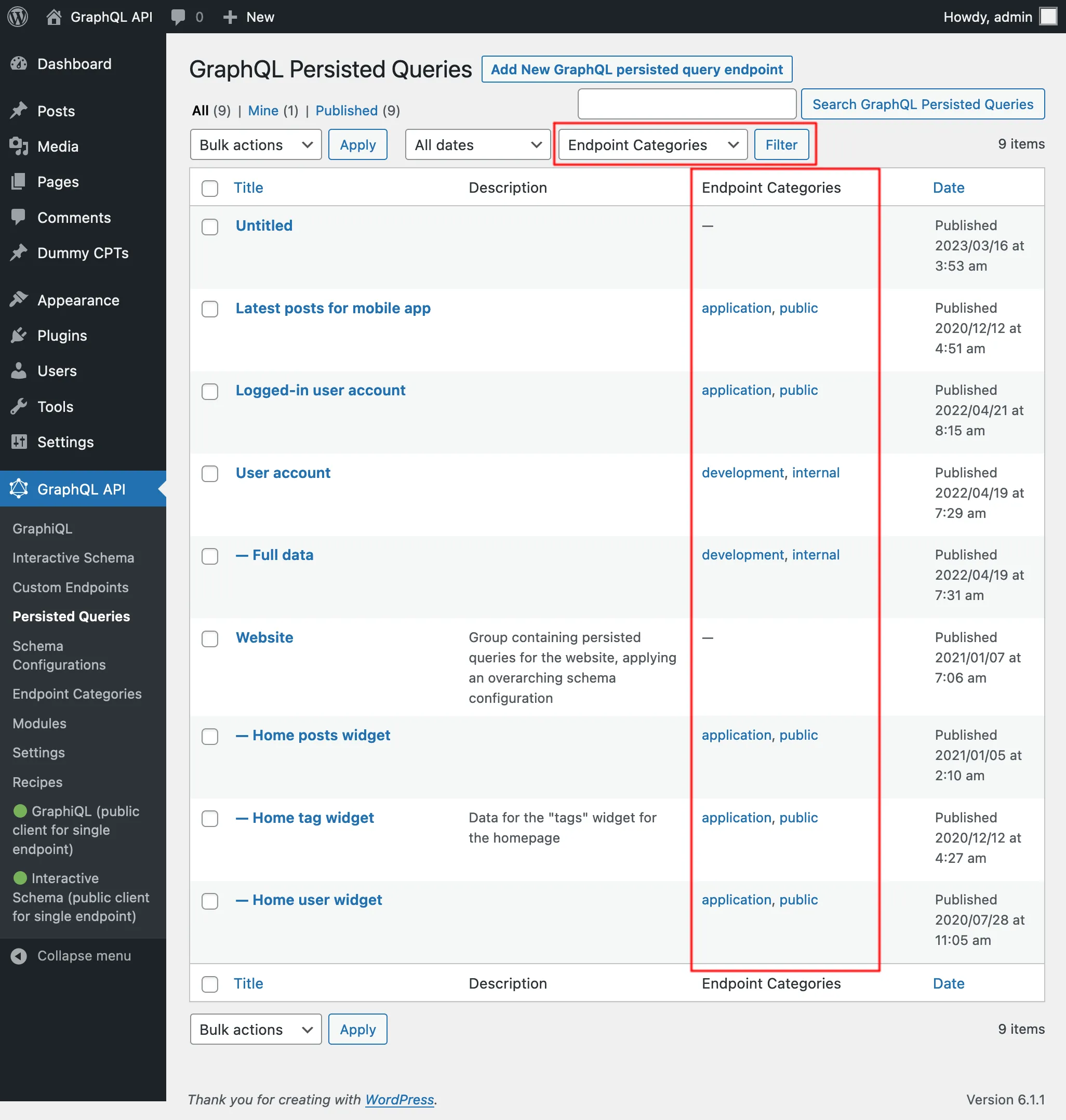
On the list of Persisted Queries, we can visualize their categories and, clicking on any category link, or using the filter at the top, will only display all entries for that category:
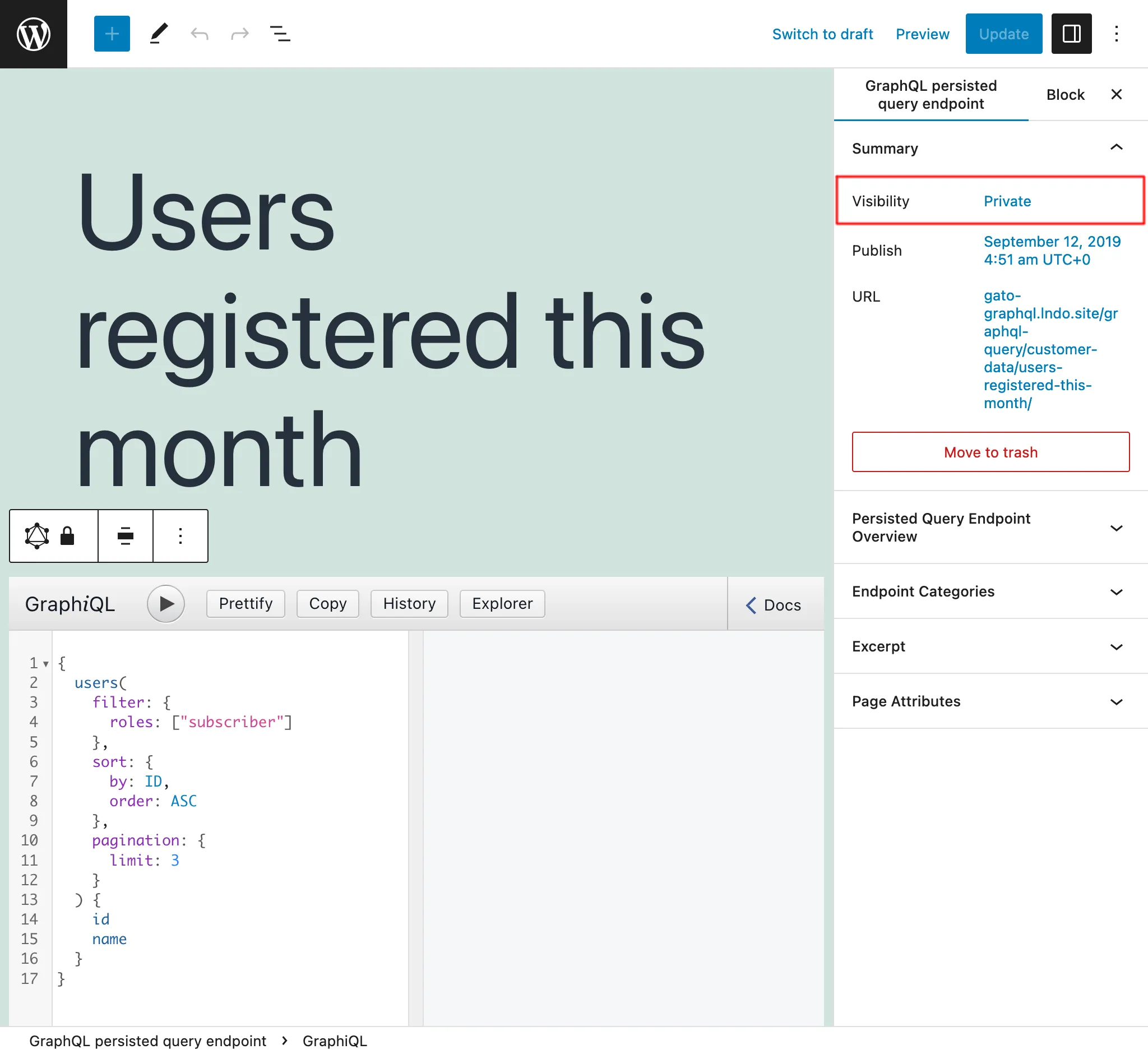
Private persisted queries
By setting the status of the Persisted Query as private, the endpoint can only be accessed by the admin user. This prevents our data from being unintentionally shared with users who should not have access to the data.
For instance, we can create private Persisted Queries that help manage the application, such as retrieving data to create reports with our metrics.
Password-protected persisted queries
If we create a Persisted Query for a specific client, we can assign a password to it, to provide an additional level of security that only that client will access the endpoint.
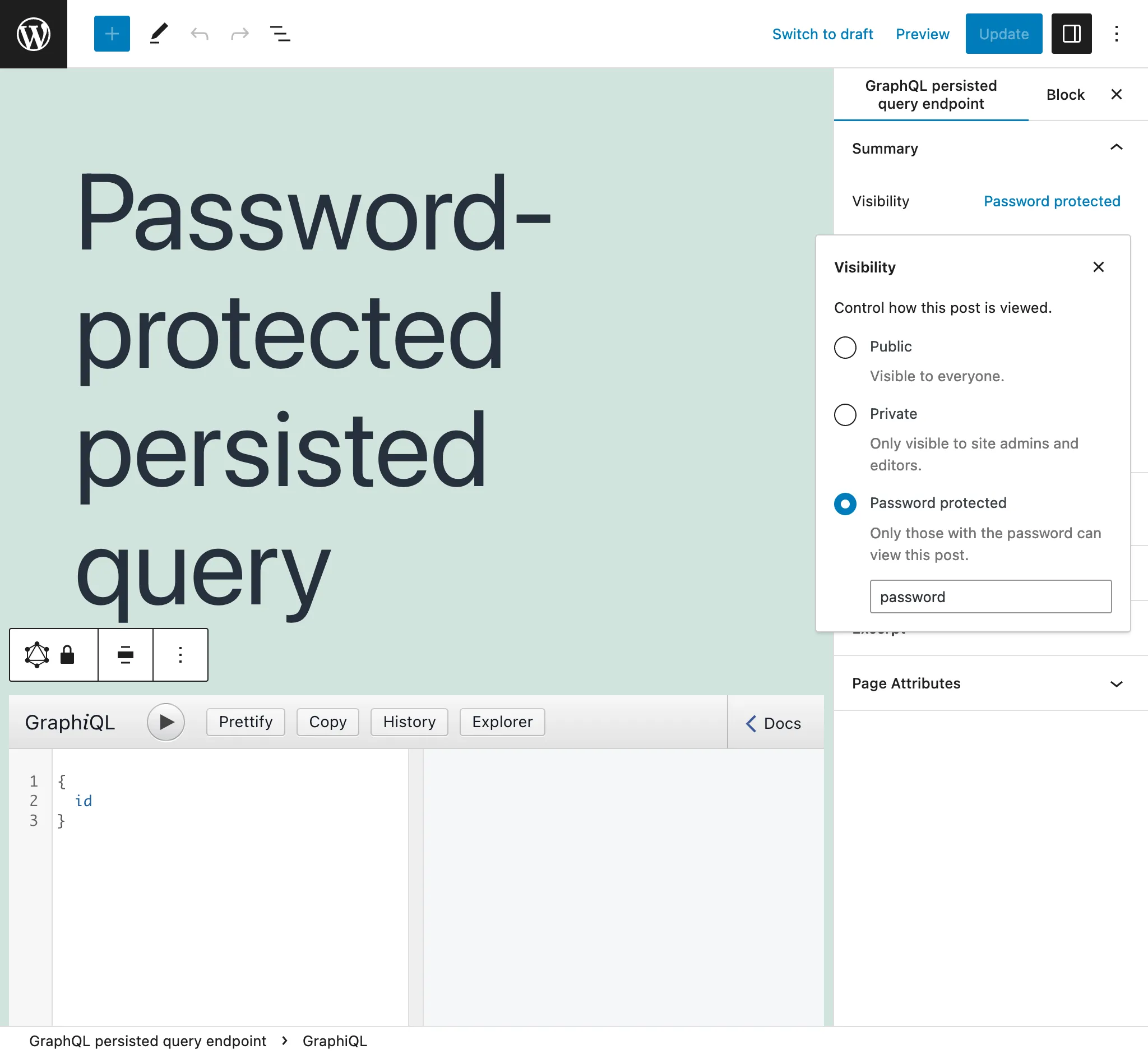
When first accessing a password-protected persisted query, we encounter a screen requesting the password:
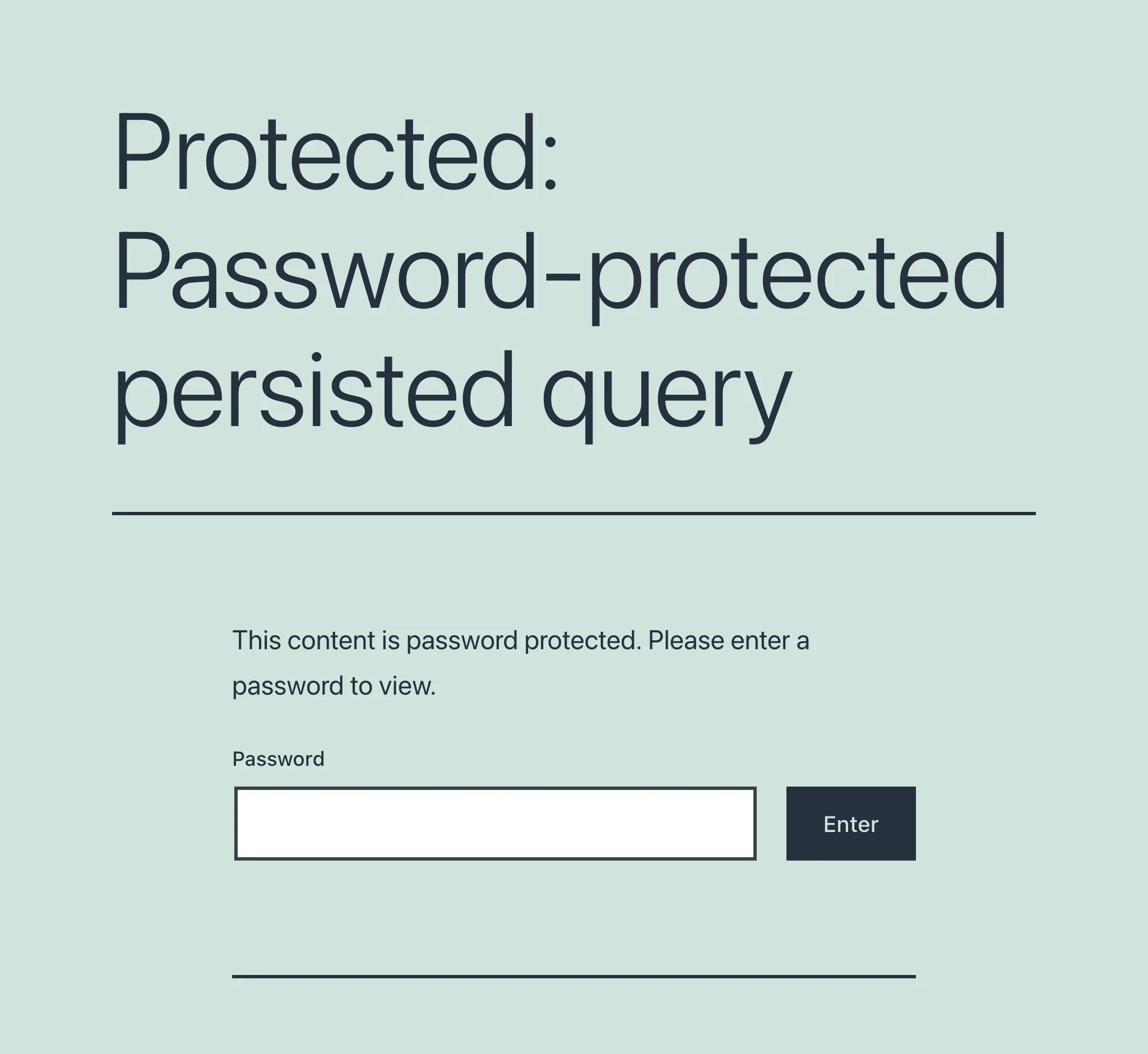
Once the password is provided and validated, only then the user will access the intended endpoint.
Making the persisted query dynamic via URL params
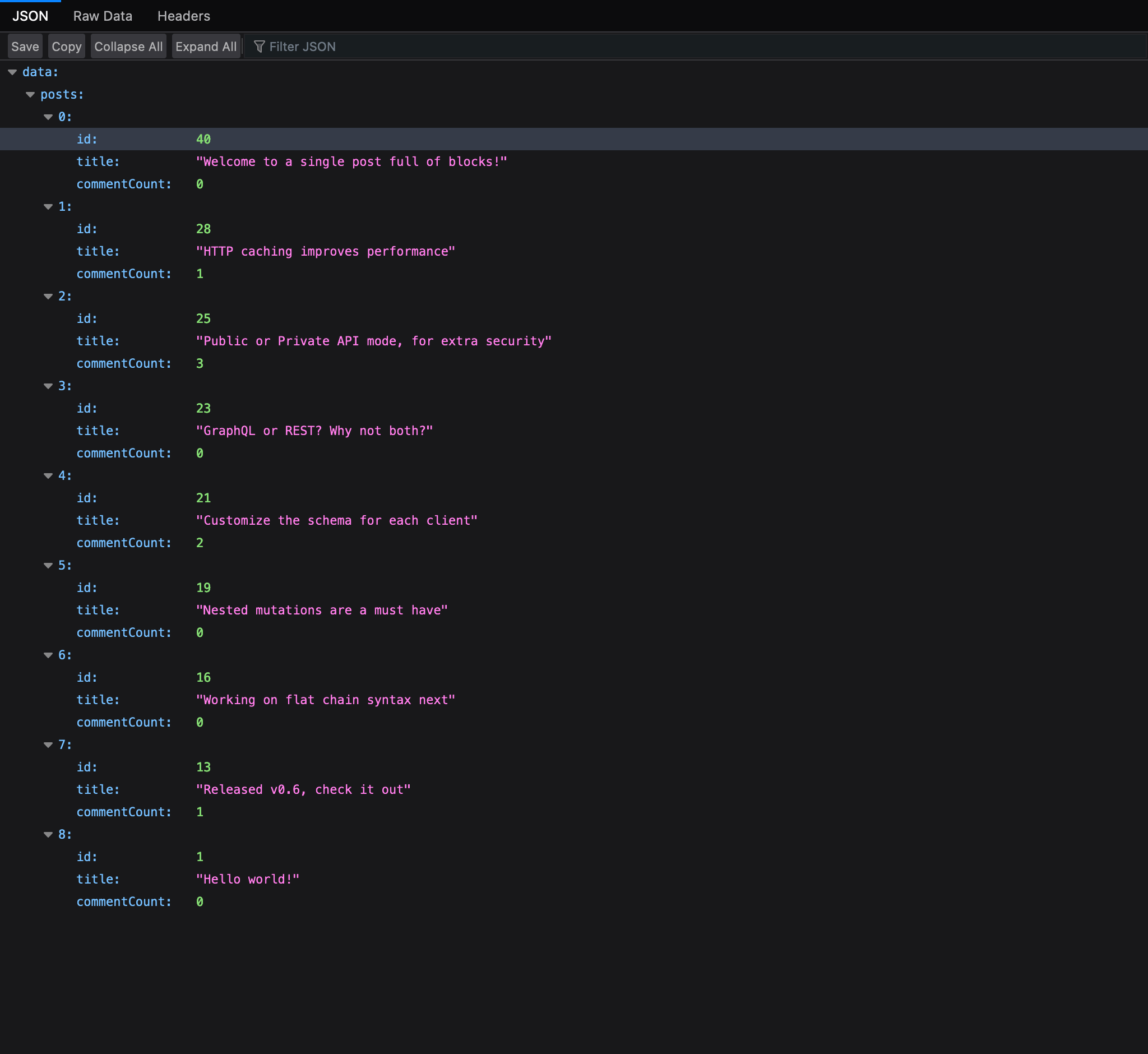
The value for each variable can be set via a URL param (with the variable name) when executing the persisted query. If option "Do URL params override variables?" is enabled, then the URL param will take priority. Otherwise, the value defined in the variables dictionary will take priority (if any).
For instance, in this query, the number of results is controlled via variable $limit, with a default value of 3:
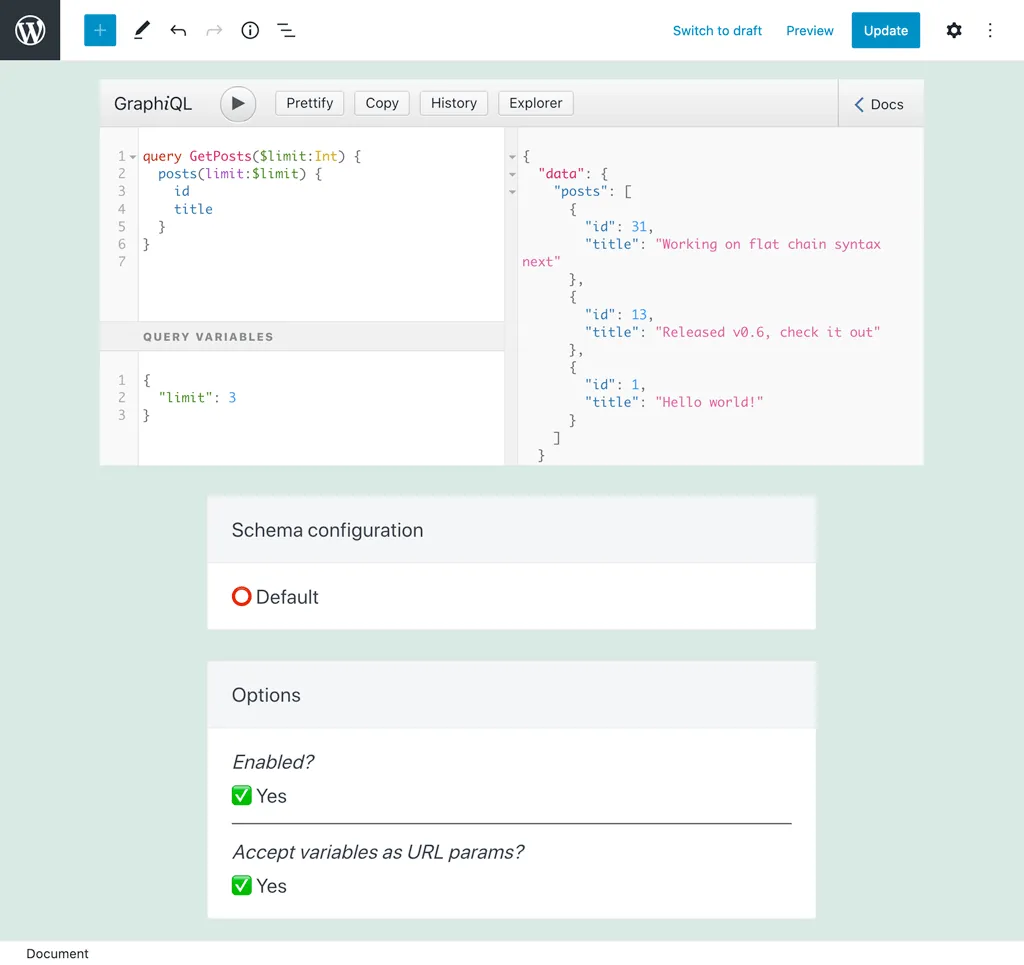
When executing this persisted query, passing ?limit=5 will execute the query returning 5 results instead: