
Manipulating the field resolution order
The goal for the @export directive provided by Multiple Query Execution is to export the value of a field (or set of fields) into a variable, to be used somewhere else in the query.
This directive would not work if reading the variable takes place before exporting the value into the variable. Hence, the engine needs to provide a way to control the field execution order.
Gato GraphQL provides a way to manipulate the field execution order through the query itself. The engine loads data in iterations for each type, first resolving all fields from the first type it encounters in the query, then resolving all fields from the second type it encounters in the query, and so on until there are no more types to process.
For instance, the following query involving objects of type Director, Film and Actor:
{
directors {
name
films {
title
actors {
name
}
}
}
}...is resolved by the GraphQL engine in this order:

If after processed, a type is referenced again in the query to retrieve non-loaded data (eg: from additional objects, or additional fields from already-loaded objects), then the type is added again at the end of the iteration list.
For instance, if we also query the Actor's preferredDirector field (which returns an object of type Director) like this:
{
directors {
name
films {
title
actors {
name
preferredDirector {
name
}
}
}
}
}...then the GraphQL engine processes the query in this order:

Let's see how this plays out for executing @export in a single query. For our first attempt, we create the query as we would normally do, without thinking about the execution order of the fields:
query GetPostsAuthorNames {
user(by: { id: 1 }) {
name @export(as: "authorName")
}
posts(filter: { search: $authorName }) {
id
title
}
}When running the query, it produces this response:
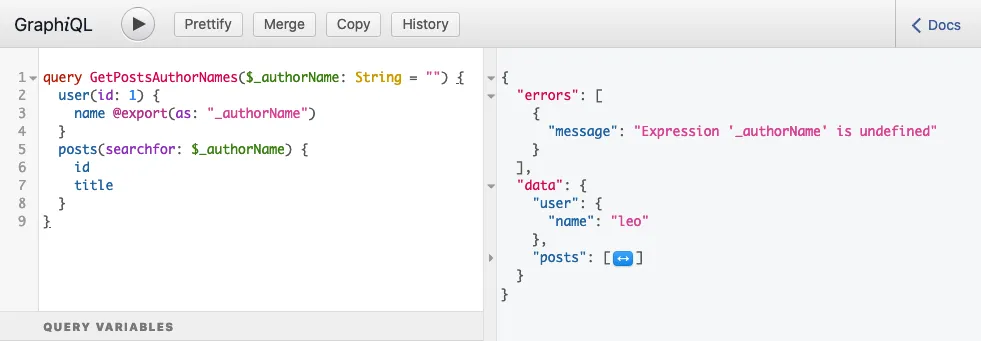
...which contains the following error:
{
"errors": [
{
"message": "Expression 'authorName' is undefined",
}
]
}This error means that, by the time variable $authorName was read, it had not been set yet; it was undefined.
Let's see why this happens. First, we analyze what types appear in the query, added as comments below:
# Type: Root
query GetPostsAuthorNames {
# Type: User
user(by: {id: 1}) {
# Type: String
name @export(as: "authorName")
}
# Type: Post
posts(filter: { search: $authorName }) {
# Type: ID
id
# Type: String
title
}
}To process the types and load their data, the data-loading engine adds the query type Root into a FIFO (First-In, First-Out) list, thus making [Root] the initial list passed to the algorithm, and then iterates over the types sequentially, like this:
| # | Operation | List |
|---|---|---|
| 0 | Prepare FIFO list | [Root] |
| 1a | Pop the first type of the list (Root) | [] |
| 1b | Process all fields queried from the Root type:→ user(by: {id: 1})→ posts(filter: { search: $authorName })Add their types ( User and Post) to the list | [User, Post] |
| 2a | Pop the first type of the list (User) | [Post] |
| 2b | Process the field queried from the User type:→ name @export(as: "authorName")Because it is a scalar type ( String), there is no need to add it to the list | [Post] |
| 3a | Pop the first type of the list (Post) | [] |
| 3b | Process all fields queried from the Post type:→ id→ titleBecause these are scalar types ( ID and String), there is no need to add them to the list | [] |
| 4 | List is empty, iteration ends. |
Here we can see the problem: @export is executed on step 2b, but it was read on step 1b.
It is here that we need to control the field execution flow. The solution implemented is to delay when the exported variable is read, achieved by artificially querying for field self from type Root.
The self field, as its name indicates, returns the same object; applied to the Root object, it returns the same Root object. You may wonder: "if I already have the root object, then why would I need to retrieve it again?". Because then the engine's algorithm will need to add this new reference to Root at the end of the FIFO list, and we can deliberately distribute the queried fields before or after every one of these iterations.
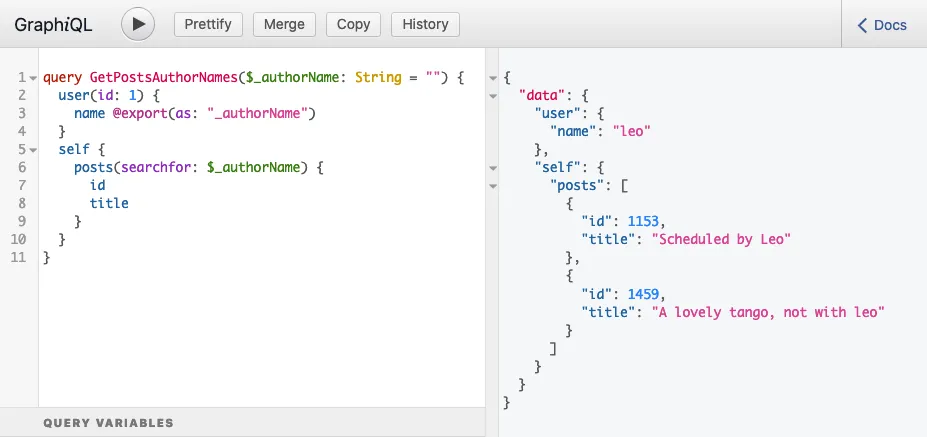
That's why field posts(filter:{ search: $authorName }) is placed inside a self field in the query above, and running the query produces the expected response:
query GetPostsAuthorNames {
user(by: {id: 1}) {
name @export(as: "authorName")
}
self {
posts(filter: { search: $authorName }) {
id
title
}
}
}
Let's explore the order in which types are processed for this query, to understand why it works well:
| # | Operation | List |
|---|---|---|
| 0 | Prepare FIFO list | [Root] |
| 1a | Pop the first type of the list (Root) | [] |
| 1b | Process all fields queried from the Root type:→ user(by: {id: 1})→ selfAdd their types ( User and Root) to the list | [User, Root] |
| 2a | Pop the first type of the list (User) | [Root] |
| 2b | Process the field queried from the User type:→ name @export(as: "authorName")Because it is a scalar type ( String), there is no need to add it to the list | [Root] |
| 3a | Pop the first type of the list (Root) | [] |
| 3b | Process the field queried from the Root type:→ posts(filter:{ search: $authorName })Add its type ( Post) to the list | [Post] |
| 4a | Pop the first type of the list (Post) | [] |
| 4b | Process all fields queried from the Post type:→ id→ titleBecause these are scalar types ( ID and String), there is no need to add them to the list | [] |
| 5 | List is empty, iteration ends. |
Now, we can see that the problem has been resolved: @export is executed on step 2b, and it is read on step 3b.
Multiple Query Execution does exactly this when decoupling queries: it converts the GraphQL document adding self fields, to have the fields in every operation be executed only after all the fields in all previous operations have been resolved.